Post-Fusaka Ethereum: What Has Happened So Far?
A detailed look at the incidents, recovery, and the network’s state after Ethereum’s latest upgrade.

 ×
×
Join Our Internship Program
Apply Now →Ethereum’s Fusaka upgrade went live without major drama at the protocol level, but the hours that followed surfaced several unexpected behaviors across the network. None of the issues threatened overall chain safety, yet they exposed important lessons about client implementations, state regeneration, data availability, fork-choice behavior under stress & coordination between Execution Layer (EL) & Consensus Layer (CL) teams.
In the days after Fusaka, developers collected incident reports, shared preliminary analyses & started shipping mitigations. From Prysm’s participation drop to late-delivery reorgs & data availability warnings, the post-Fusaka period has already begun to shape priorities for future upgrades like Glamsterdam & Heka.
- Prysm Participation Drop
- Data Availability: Dasmon Missing Data
- Nethermind–Nimbus Validation Mismatch
- Late Delivery Reorgs & Fork Choice
- What It Means for Ethereum Going Forward
Prysm Participation Drop
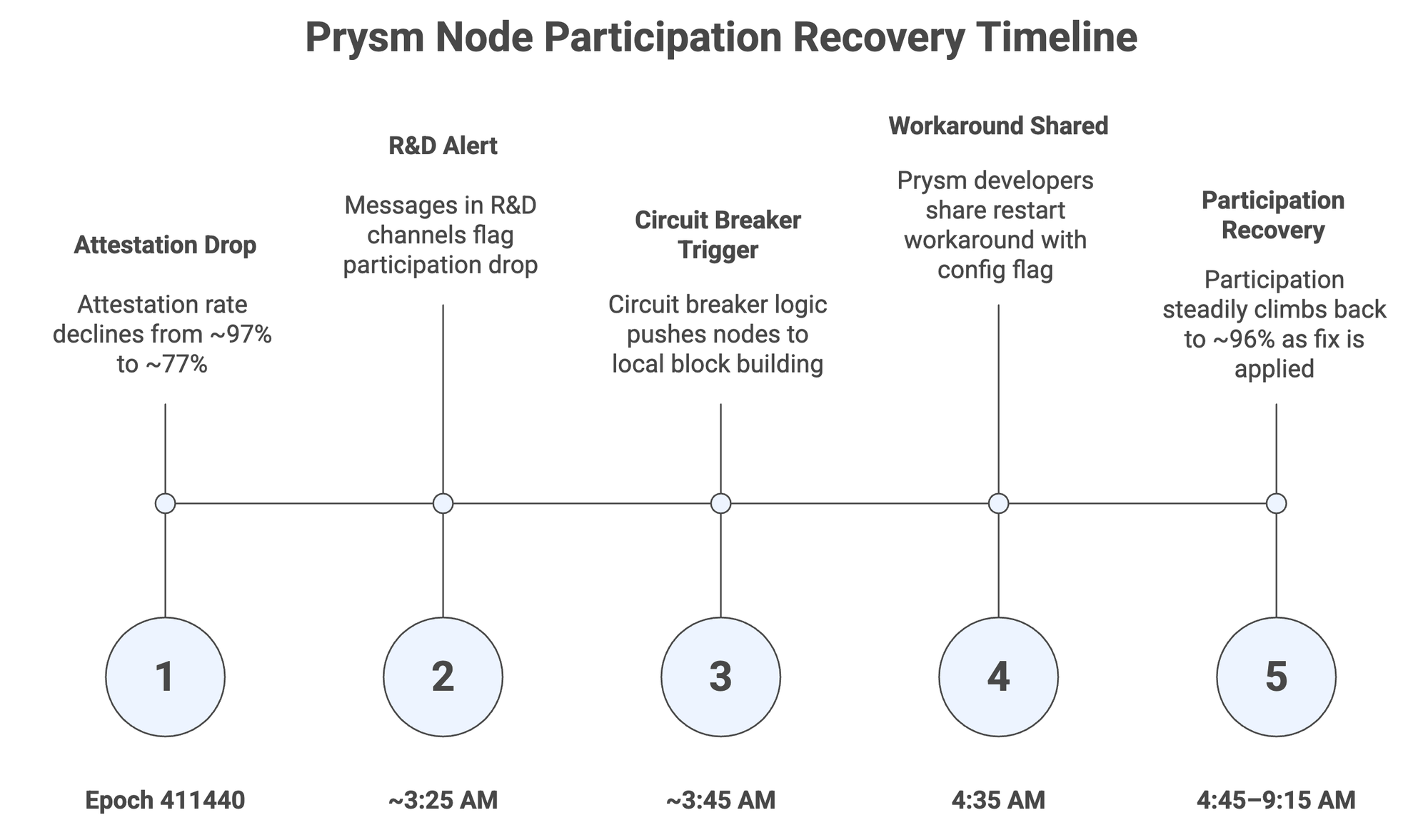
The most visible Fusaka-related incident involved Prysm validators. Around epoch 411440, Ethereum’s attestation participation rate, i.e., typically around 97% suddenly fell to roughly 77%, a drop that closely matched Prysm’s estimated share of the validator set.
🚨 We have identified the issue and have a quick workaround. All nodes should disable Prysm to unnecessarily generate old states to process outdated attestation. To do this, simply add the following flag to your beacon node. This flag works with v7.0.0 and you do not need to…— Prysm Ethereum Client (@prylabs) December 4, 2025
Prysm nodes were being dragged into expensive work by stale attestations, which triggered regeneration of older states instead of operating on the most recent head. This behavior is related to a heuristic first introduced in Capella, where clients could reuse the head state when the target epoch matched the current epoch.
Fusaka’s refactor broadened what counted as a “valid checkpoint,” accidentally recreating conditions similar to the Capella-era outage. As this was happening:
- Fork choice produced many short, stale branches.
- Block delivery times grew significantly, starting around block 23937064.
- Some nodes switched away from the builder API & fell back to local block building to keep producing blocks.
Despite the disruption, the chain did not halt. Consensus continued, but overall participation looked unhealthy until Prysm operators applied a workaround.
Importantly, no client release or full resync was required. The network started recovering quickly once the configuration-based solution was communicated, & follow-up work is already underway to ship a robust fix along with a full post-mortem.
Data Availability: Dasmon Missing Data
Another post-Fusaka signal came from Dasmon, a data availability probing tool. After the upgrade, many probes reported missing data.
Preliminary analysis suggests that these reports are likely tied to late blob deliveries rather than a deeper structural failure. In other words, data did arrive, but not always within the ideal time window for the probes, causing them to flag “missing” results.
The relevant probes can be viewed here. For now, the incident has not been associated with widespread rollup failures or catastrophic data loss, but it has strengthened the argument for improving:
- Blob propagation pipelines
- Monitoring around data availability
- The tooling used to interpret & surface these metrics in real time
As Ethereum prepares for higher blob counts & more rollup activity, the post-Fusaka data from Dasmon has become a useful diagnostic hint.
Nethermind–Nimbus Validation Mismatch
A separate, more targeted issue involved Nethermind running together with Nimbus as the CL client. Nethermind reported a wrong invalid block at slot 13164552 in that configuration. Other clients did not consider the block invalid, which raised the possibility of a client-specific bug.
Further investigation found:
- The bug seemed to appear only when Nethermind was compiled in a specific Nix-based environment.
- It affected very few users in practice.
- The issue might be related more to build differences than to core consensus logic.
The corresponding issue is tracked here. While limited in scope, this incident reinforces the importance of:
- Reproducible builds across different environments.
- Cross-client testing in realistic combinations (e.g., Nethermind + Nimbus).
- Clear reporting channels so rare edge cases can be caught before they spread.
Late Delivery Reorgs & Fork Choice
One of the more subtle but technically interesting behaviors observed after Fusaka involved late-block delivery & how Ethereum’s fork-choice rule handles such cases. A key example comes from slot 13164887:
- The block for this slot arrived 4.65 seconds late, which is relatively slow in a 12-second slot regime.
- It received only two head votes, which under normal circumstances would usually lead to it being orphaned.
- However, a subsequent block was proposed on top of this late-arriving block.
- That child block received enough attestations that, when the fork-choice rule evaluated the full tree, the parent (the late block) became part of the canonical chain.
Two Reth issues have been opened to investigate whether Fusaka’s changes interacted with these conditions in any unexpected way:
The episode is now a reference case for thinking about latency, attestations & fork choice, especially as block builders, relays & rollups interact more closely.
What It Means for Ethereum Going Forward
Viewed together, the post-Fusaka incidents are less a sign of systemic weakness & more a stress test of Ethereum’s operational maturity. Key takeaways:
- Client heuristics need careful upgrading: The Prysm incident shows how seemingly small changes to state reconstruction logic can have large network effects when they interact with real-world attestation patterns.
- Build environments matter as much as code: The Nethermind–Nimbus mismatch under a specific Nix build path underlines the need for reproducible builds, shared CI patterns & cross-environment testing.
- Fork choice under latency is not theoretical anymore: The slot 13164887 reorg scenario is a live example of LMD-GHOST handling delayed blocks in complex ways. This is critical knowledge as Ethereum pushes toward more specialized block builders & higher network load.
All of these lessons are already feeding back into upgrade planning. In discussions for Glamsterdam & the future Heka upgrade, client teams are prioritizing:
- Cleaner state & attestation logic.
- Better blob propagation mechanisms.
- Out-of-protocol improvements like sparse block pools.
- Clearer incident playbooks & documentation.
Fusaka did not break Ethereum, but it did reveal exactly how a large, decentralized network behaves under edge-case conditions. A temporary drop in Prysm participation, data availability warnings, rare client mismatches & unusual fork-choice outcomes all became live-fire tests of Ethereum’s resilience.
The network bent but did not come close to breaking. Validators recovered, blocks kept finalizing & developers responded quickly with mitigations & deeper investigations.
If you find any issues in this blog or notice any missing information, please feel free to reach out at yash@etherworld.co for clarifications or updates.
Related Articles
- Ethereum Launches $2 Million Fusaka Audit Contest to Fortify Protocol Security
- Ethereum Developers Announce "The Weld" Repository Merger
- Ethereum Developers Target September 22 for Holesky Client Releases
- Ethereum Developers Face Blockers in Shadowfork Testing Ahead of Fusaka
- A New Playbook for Ethereum: Fusaka Rethinks Testnet & Mainnet Schedules
Disclaimer: The information contained in this website is for general informational purposes only. The content provided on this website, including articles, blog posts, opinions, & analysis related to blockchain technology & cryptocurrencies, is not intended as financial or investment advice. The website & its content should not be relied upon for making financial decisions. Read full disclaimer & privacy policy.
For Press Releases, project updates & guest posts publishing with us, email contact@etherworld.co.
Subscribe to EtherWorld YouTube channel for ELI5 content.
Share if you like the content. Donate at avarch.eth.
You've something to share with the blockchain community, join us on Discord!
Author

Yash Kamal Chaturvedi is a Blockchain Content & Ops Specialist at Avarch LLC, writing on Ethereum & governance since 2021. Covers ACD/ACDE calls, EIPs, upgrades, staking, security & ecosystem trends.



