
 ×
×
Join Our Internship Program
Apply Now →Merkle Tree
Merkle Tree also known as 'hash tree' is a data structure in cryptography in which each leaf node is a hash of a block of data, and each non-leaf node is a hash of its child nodes. In the most general sense, Merkle tree (named after Ralph Merkle who patented it in 1979) is a way of hashing many “chunks” of data together which relies on splitting the chunks into nodes, where each node contains only a few chunks, then taking the hash of each node and repeating the same process, continuing to do so until the total number of hashes remaining becomes only one called the root hash. It is a generalization of hash lists and hash chains.
The most common and simple form of Merkle tree is the binary Mekle tree, where a node always consists of two adjacent chunks or hashes. It is a kind of 'hash tree' where every single node of the tree is the hash of the two nodes below it. However, a Merkle tree can be created as an n-nary tree, with n children per node.
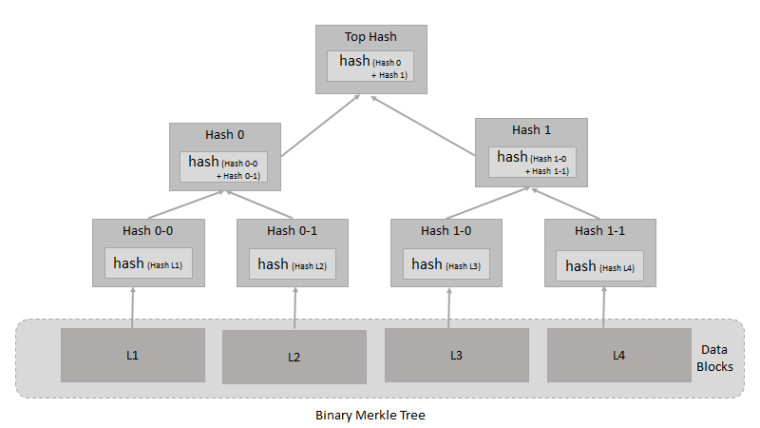
Fig: Binary Merkle Tree (diagram taken from Wikipidia)
Here, we see an input of data is broken up into blocks labeled L1, L2, L3 and L4. Each of these blocks are hashed using some cryptographic hash function. Then each pair of nodes are recursively hashed until we reach the root node, which is a hash of all nodes below it. SHA-2 is the most popular cryptographic hash function. If the hash tree only needs to protect against unintentional damage, CRCs can be used too.
Binary Merkle trees are very reliable data structures for authenticating information that is in a “list” format; essentially, a series of chunks one after the other. For transaction trees, they are also good because it does not matter how much time it takes to edit a tree once it’s created, as the tree is created once and then forever frozen solid.
Benefits and Utility
The benefit of this hashing algorithm is that it allows for a neat mechanism known as Merkle proofs. A Merkle proof consists of
a chunk,
the root hash of the tree,
the “branch” consisting of all of the hashes going up along the path from the chunk to the root.
Someone reading the proof can verify that the hashing (at least for that branch), is consistent going all the way up the tree, and therefore that the given chunk actually is at that position in the tree. Example, a user wants to do a key-value lookup on the database (eg. “tell me the object in position 612345”) can ask for a Merkle proof, and upon receiving the proof verify that it is correct, and therefore that the value received actually is at position 612345 in the database with that particular root.
Merkle Trees protocol allows for efficiently verifiable proofs that a transaction was included in a block.
If you have all the transactions / entire database then you can know your account balance, what some body's storage / account and other information. But you don’t have enough resources to process the entire blockchain. In this situation, Merkle Trees protocol helps. It allows data to store in smaller chunks hash of hash. So, instead of downloading the entire block; all we download is the Merkle branch that verifies that hashes inside of the branch is consistent. You can verify the Merkle branch with block header. It is basically taking help of miners to verify that this piece of state is what it is saying.
In distributed (peer-to-peer) network, the same data exists in multiple locations and hence data verification is very important. Merkle trees allow efficient and secure verification of the contents in distributed systems. This is efficient because it uses hashes instead of full files. Hashes are ways of encoding files that are much smaller than the actual file itself. Merkle tree allows a simpler mechanism for authenticating a small amount of data like hash, as well as authenticate large databases of potentially unbounded size. The original application of Merkle proofs was in Bitcoin, as described and created by Satoshi Nakamoto in 2009. The Bitcoin blockchain uses Merkle proofs in order to store the transactions in every block. Currently, it is used in few other peer-to-peer networks such as Ethereum, Tor, and Git.
Merkle Tree in Blockchain
The benefit of using the Merkle Tree in blockchain is that instead of downloading every transaction and every block, a “light client” can only download the chain of block headers.
In blockchain, every block contains few hundreds of transactions data. If someone needs to verify existence of a specific transaction in a block, then he doesn't have to download the entire block. Downloading a set of branch of this tree which contains this transaction is enough. We check the hashes which are just going up the branch (relevant to my transaction). If these hashes check out good, then we know that this particular transaction exist in this block.
Block Header : An 80-byte chunks of data belonging to a single block which is hashed repeatedly to create proof of work is called as block header. It contains five things:
A hash of the previous header
A timestamp
A mining difficulty value
A proof of work nonce
A root hash for the Merkle tree containing the transactions for that block.
If the light client wants to determine the status of a transaction, it can simply ask for a Merkle proof showing that a particular transaction is in one of the Merkle trees whose root is in a block header for the main chain.
Block : A block in the ethereum blockchain consists of a header, a list of transactions, and a list of uncle blocks. Included in the header is a transaction root hash, which is used to validate the list of transactions. Transactions are sent over the wire from peer to peer as a simple list. They must be assembled into a special data structure called a trie to compute the root hash. Uncle blocks are the stale blocks re-included in the blockchain.
The state in header needs to be frequently updated: the balance and nonce of accounts is often changed, and what’s more, new accounts are frequently inserted, and keys in storage are frequently inserted and deleted.
Light Client : A client that accesses the blockchain without processing every block and without downloading every transaction in the chain is called as “light client”. This is needed for clients accessing blockchain to verify data with a little low memory device such as mobile phone.
Merkle Tree Protocol in Ethereum
Creating Ethereum system without Merkle tree could be like creating giant block headers that directly contain every transaction. This could have posed large scalability challenges and in long term making it out of reach of all except for the most powerful computers in the world.
The concept of Merkle tree is introduced in Ethereum to allow for compact and efficiently verifiable proofs that a transaction was included in a block. This is already in existing in Bitcoin. Ethereum takes the Merkle tree concept of Bitcoin implementation a step further.
Every block header in Ethereum contains not just one Merkle tree, but three trees for three kinds of objects:
Transactions
Receipts (essentially, pieces of data showing the effect of each transaction)
State
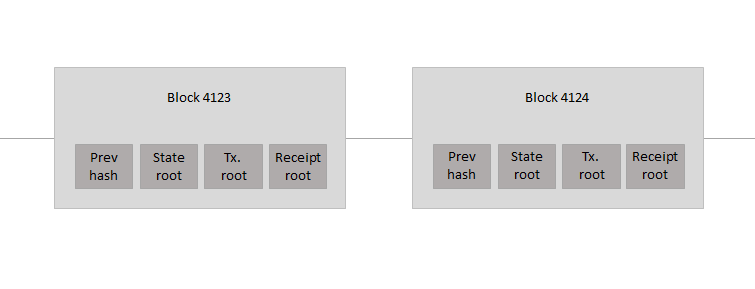
Fig : Block Header in Ethereum
This allows for a highly-advanced light client protocol that allows light clients to easily make and get verifiable answers to many kinds of queries:
Has this transaction been included in a particular block? (handled by Transaction tree)
Tell me all instances of an event of type X (eg. a crowdfunding contract reaching its goal) emitted by this address in the past 30 days. (handled by Receipt tree)
What is the current balance of my account? (handled by State tree)
Does this account exist? (handled by State tree)
Pretend to run this transaction on this contract. What would the output be? (handled by State tree).
Merkle Patricia tree
Merkle tree used in Ethereum is more complex than simple binary Merkle tree. This is called as the “Merkle Patricia tree”. Patricia tree is used in order to allow efficient insert / delete operations.
PATRICIA is abbreviation to Practical Algorithm To Retrieve Information Coded in Alphanumeric (source: original paper by Donald R. Morrison).
Patricia Tree provide a cryptographically authenticated data structure that can be used to store all (key, value) bindings, although for the scope of this paper we are restricting keys and values to strings (to remove this restriction, just use any serialization format for other data types).
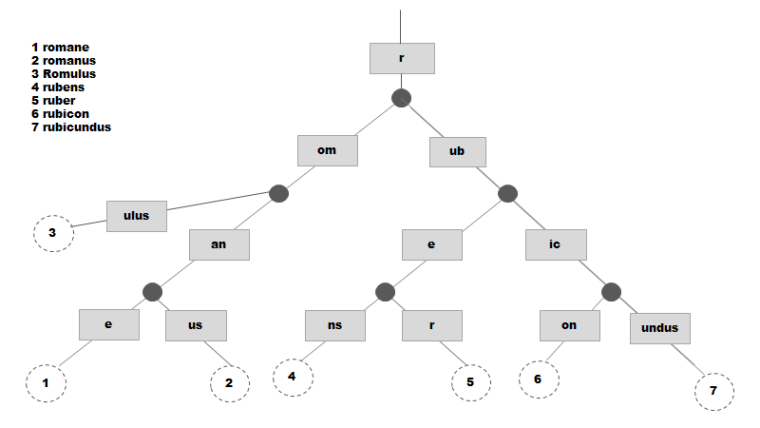
Fig: An example of a radix tree (Source :Wikipedia)
A Patricia tree is a binary radix tree (also known as radix trie). It is a data structure that represents a space-optimized trie (digital tree) in which each node that is the only child is merged with its parent.
To implement Particia tree in Ethereum, couple of modification are introduced to boost efficiency. In a normal radix tree, a key is the actual path taken through the tree to get to the corresponding value. That is, beginning from the root node of the tree, each character in the key tells you which child node to follow to get to the corresponding value, where the values are stored in the leaf nodes that terminate every path through the tree. In Ethereum, hexadecimal is used - X characters from an 16 character "alphabet". Hence nodes in the trie have 16 child nodes (the 16 character hex "alphabet") and a maximum depth of X. A hex character is referred to as a 'nibble'.
Read more arti

0-at-10.57.18-AM.png)](/2019/01/30/dksvp2p-wire-protocol-kademlia-distributed-hash-table/)
- Introducing web3 commands to browser
- Understanding Ethereum Light Node
- Understanding the concept of Private Key, Public Key and Address in Ethereum Blockchain
- Certificate on IPFS and Ethereum
- Running Ethereum testnet using Geth
- Installing geth on ubuntu 16.10
For more articles on blockchain technology, follow us at Website, Twitter, Facebook, Google+, Steemit and Medium. To receive weekly newsletter, subscribe here. Publish Press Release and list ICO at our website.
Author
EtherWorld, a project by Avarch, is a leading independent Ethereum media platform since 2017, sharing news, technology, and ecosystem projects. Popular for All Core Dev summaries, EIP explainers, community-driven storytelling across blogs & videos.



