Chaos Engineering of Ethereum Clients
A research report by Long Zhang, Javier Ron, Benoit Baudry, and Martin Monperrus of KTH Royal Institute of Technology, Sweden.

 ×
×
Join Our Internship Program
Apply Now →As a distributed system, the resilience of the whole Ethereum network is rooted in the resilience of each participating Ethereum client. Testing and improving the resilience of Ethereum client implementations is of utmost importance. Ethereum clients indeed have many reasons for malfunctioning such as operating system overload, memory errors, network partitions, etc. While research on error handling and fault injection is abundant1, there is little research work on assessing the resilience of blockchain clients and Ethereum.
In this post, we share novel insights on benchmarking and improving the resilience of Ethereum clients. For more information, see the long paper or the youtube video.
Chaos Engineering in a Nutshell
If anything can go wrong, it will.
— Murphy's law
Chaos engineering is a methodology to assess and improve the error-handling mechanisms of software systems. To perform chaos engineering, developers actively inject failures in the system in production, in a controlled manner. They then compare the behavior observed during fault injection with the normal behavior. A similar behavior indicates resilience to the injected faults, while discrepancies between both behaviors indicate resilience issues.
In the context of an Ethereum client, no one can test offline all the problems that it will meet after it is deployed in production. The main reason is that it is impossible to reproduce the actual Ethereum blockchain evolution at scale. Chaos engineering is fit to address this challenge, as it triggers an Ethereum client's error-handling code while the client is executing on mainnet. The chaos engineering perturbations are done in production, while the Ethereum client participates in the blockchain consensus and validation process. To sum up, our key insight is that chaos engineering is a great technique to analyze the resilience of blockchain systems.
Design of ChaosETH
Regardless of how an Ethereum client is deployed, it has to be executed on top of an operating system. The operating system is responsible for providing the Ethereum client access to critical resources such as network and storage, and it does so by means of system calls. For example, on May 9th 2021 a 1-minute execution of the Geth client triggered more than one million system calls (1,128,215), of 36 different syscall types such as read and write.
It is interesting to note that, even if the client was behaving normally, not all system call invocations were successful: 14,640 invocations failed during within the same minute-long observation period, with 9 different kinds of error codes. All those natural errors do not crash the Geth client.
Beyond those natural errors, what if the operating system becomes even more unstable2?
?
- Is the Ethereum client still able to function correctly?
- Would it crash?
- Would it run in a degraded mode?
In order to explore these questions, we use chaos engineering. We implement a research prototype called ChaosETH. ChaosETH is designed with three components, and produces one resilience report, as summarized in Figure 1. ChaosETH operates on one single node (signified by the column titled Ethereum Node in Figure 1). In this specific Ethereum node, ChaosETH is attached to the client process during its execution, for example attached to Geth. The steady state analyzer collects monitoring metrics and infers the system's steady state. Then, the system call error injector injects different error codes into some system call invocations in a controlled manner. With the help of the orchestrator, ChaosETH systematically conducts chaos engineering experiments. Finally, ChaosETH produces a resilience report with respect to system call errors for developers.
Putting all of the above together, let the Geth developers hypothesize that a Geth client does not crash when half of the read system call invocations fail with the error code EAGAIN. Then ChaosETH conducts a chaos engineering experiment and actively injects EAGAIN errors when the system call read is invoked. Then, the developers are told “Yes, Geth can sustain a 50% error rate” or “No, Geth crashes under this scenario”. Table 1 presents the complete resilience report for Geth.
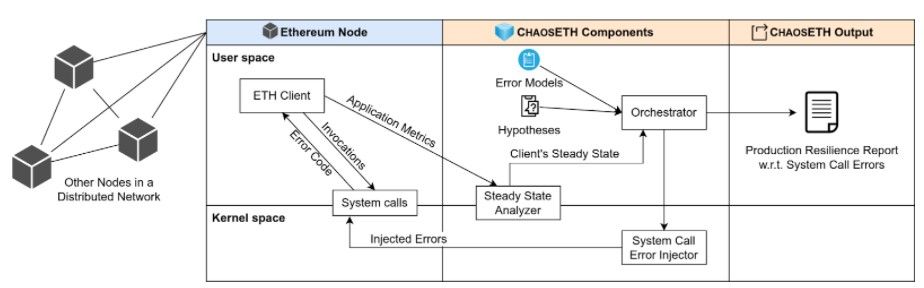
Figure 1. The Components of ChaosETH
| Hypothesis | Geth does not crash when more than half of invocations to read fail with error code EAGAIN. |
|---|---|
| Experiment Error Model | When system call read is invoked, ChaosETH injects an EAGAIN error with a 50% possibility. |
| Experiment Record | - Exeriment was done from time1 to time2 - Geth logs and monitored metrics from time1 to time2 - Syscall read was invoked X times - Syscall read was failed with error EAGAIN Y times - Geth crashed at time2 (The experiment was stopped when Geth crashed) |
| Results | Since Geth crashed when system call invocations to read failed with EAGAIN errors, the hypothesis is falsified. |
Table 1. Example of Resilience Report
Steady State Analyzer
Geth, besu and nethermind all provide a certain level of observability. For example, when option --metrics is specified, a Geth client can expose more than 500 different metrics. So, the steady state analyzer uses metrics directly taken from an Ethereum client’s monitoring module.
System Call Error Injector
In order to conduct chaos engineering experiments, we need to inject chaos. ChaosETH uses a system call error injector. When the injector is activated, it listens to system call invocation events, and it replaces the original return code with an error code. In ChaosETH, the error injector uses an error injection model to describe its injection strategy. The error injection model is a triple (s, e, r) that states that the system call s is injected with error code e under the error rate r ∈ [0,1]. The error rate is a likelihood that describes the probability of replacing the return code by error code e when system call s is invoked during an experiment. Let us take the error injection model (read, EAGAIN, 0.5) as an example. The first element read means that the injector focuses on invocations to system call read. EAGAIN is the error code to be injected. 0.5 indicates that there is a 50% probability that a successful return code is replaced with an error code EAGAIN. Based on Linux Programmer’s Manual, EAGAIN means that the resource being read is temporarily unavailable3.
Experiment Orchestrator
The experiment orchestrator communicates with the previous two components to conduct chaos engineering experiments. After a chaos engineering experiment, the orchestrator analyzes the client's behavior during the experiment and generates a resilience report for developers. The report presents to what extent the implementation of the Ethereum client under evaluation is resilient to the injected system call invocation errors. The client's resilience is assessed by validating chaos engineering hypotheses, as shown in the simplified example (Table 1).
In ChaosETH, there are three hypotheses about how a client reacts when errors are injected using one specific error model.
a) Non-Crash hypothesis (HN): The non-crash resilience hypothesis holds if the injected system call invocation errors do not crash the Ethereum client and the process remains alive.
On the one hand, if a client is not configured to restart automatically, a crash hurts availability. On the other hand, for some of the errors that a client cannot handle by design, a crash keeps the synchronized data safe. Anyway, it is important to verify HN so that developers can check if the client acts as expected when a specific error occurs.
b) Observability hypothesis (HO): The observability hypothesis for a metric m holds if m is influenced by error injections according to an error model.
Checking HO helps developers know whether a specific error causes side effects on the client even if the client does not crash (i.e., HN holds). From the verification of HO, developers also get a chance to improve the performance that is related to the affected metrics.
c) Recovery hypothesis (HR): The recovery hypothesis is valid if the client is able to recover to its steady state after stopping the injection of system call invocation errors.
A client that is running does not mean that it is functioning well. After handling errors in production, the client should be able to go back to its normal execution state. Verifying HR helps developers to understand whether an error causes any long-term effect such as thread hanging on a client.
Experiments on Geth v1.10.8
In this post, we share the results of our chaos engineering experiments on Gethv1.10.8, summarized in Table 2. Since there are many system call types and error codes, it is not practical to try all the combinations during our chaos engineering experiments. First, we keep the Geth client running normally and observe the system call invocation errors that naturally occur. Then, the observed system call type and the error code are kept as they are but the error rate is amplified. The chaos engineering experiments let developers explore the previous questions we asked in this post (Beyond those natural errors, what if the operating system becomes even more unstable?).
The results show that Geth indeed has different degrees of resilience with respect to system call invocation errors. For example, Geth v1.10.8 is fully resilient to the system call error model (read, EAGAIN, 0.597). When such errors are injected, Geth does not crash. The metric memory_used is observed to have a different behavior, but it gets back to normal when the error injection stops. On the contrary, a EAGAIN error to system call invocation write leads Geth to a crash. Is Geth designed to act like this? Is it better to have a retry mechanism since it is an EAGAIN error code? We leave these questions to Geth developers. By conducting chaos engineering experiments, developers of Ethereum clients can assess error-handling code in a realistic setup.
| SYSCALL | ERROR CODE | ERROR RATE | INJECTION COUNT | METRIC | HN | HO | HR |
|---|---|---|---|---|---|---|---|
| accept4 | EAGAIN | 0.6 | 476 | memory_used | ? | ⚠️ | ? |
| epoll_ctl | EPERM | 0.171 | 147 | memory_used | ? | ⚠️ | ? |
| epoll_pwait | EINTR | 0.05 | 3421 | disk_read | ? | ⚠️ | ? |
| memory_used | ? | ⚠️ | ? | ||||
| futex | EAGAIN | 0.05 | 14 | - | ⚠️ | ? | ? |
| futex | ETIME. | 0.05 | 2 | - | ⚠️ | ? | ? |
| newfstatat | ENOENT | 0.24 | 6 | disk_read | ? | ? | ⚠️ |
| memory_used | ? | ⚠️ | ? | ||||
| read | EAGAIN | 0.597 | 139 | memory_used | ? | ? | ? |
| read | ECONN. | 0.05 | 39 | memory_used | ? | ⚠️ | ? |
| recvfrom | EAGAIN | 0.6 | 678 | memory_used | ? | ⚠️ | ? |
| write | EAGAIN | 0.139 | 12 | - | ⚠️ | ? | ? |
| write | ECONN. | 0.05 | 5 | - | ⚠️ | ? | ? |
| write | EPIPE | 0.05 | 1 | - | ⚠️ | ? | ? |
| ? means a hypothesis is verified. ⚠️ means a hypothesis is falsified. ? means a hypothesis is left to be untested. For example, if HN does not hold, ChaosETH cannot further check HO and HR because the client has crashed. | |||||||
Table 2. Chaos Engineering Experimental Results on Geth v1.10.8
Conclusion
In this post, we present our research on chaos engineering for assessing the resilience of Ethereum clients in production. Our experiments show that ChaosETH is effective to detect error-handling weaknesses and strengths. The key takeaway of our experiments is that different Ethereum client implementations react differently to the same error model. In order to keep the reliability of the whole Ethereum system high, a direction for future research would be applying n-version execution for an Ethereum node, i.e. executing different clients in parallel. The n-version node would maybe be more fault-tolerant and chaos engineering can be applied again to verify the actual resilience improvement.
If you feel interested in this work, the corresponding research paper can be found here: https://arxiv.org/abs/2111.00221 The source code and the experiment data of ChaosETH can be found in our RoyalChaos GitHub repository: https://github.com/KTH/royal-chaos
Should this ring a bell, we are happy to answer your questions. You can reach us via email longz@kth.se or Telegram @gluckzhang.
This research report is authored by Long Zhang, Javier Ron, Benoit Baudry, and Martin Monperrus of KTH Royal Institute of Technology, Sweden.
________________________________________________________
1Roberto Natella, Domenico Cotroneo, and Henrique S. Madeira. Assess-ing dependability with software fault injection: A survey.ACM Comput.Surv., 48(3), February 2016.
2In this case, the possibility of facing a system call invocation error may be much higher.
3ERRNO(3) - Linux Programmer’s Manual. http://man7.org/linux/man-pages/man3/errno.3.html
Image source: KTH Main campus (Photo by: Annusyirvan Fatoni)
________________________________________________________
Disclaimer: The information contained on this webpage is for information purposes only. EtherWorld.co does NOT provide any investment advise. The content provided on this page is based on the submission made as a guest post and this is not verified by the editorial team. Readers are suggested to do your own research and verify the content before relying on them.
To publish press releases, project updates and guest posts with us, please email at contact@etherworld.co.
Subscribe EtherWorld YouTube channel for easy digestable content.
You've something to share with the blockchain community, join us on Discord!
Follow us at Twitter, Facebook, LinkedIn, Medium and Instagram.
Author
EtherWorld, a project by Avarch, is a leading independent Ethereum media platform since 2017, sharing news, technology, and ecosystem projects. Popular for All Core Dev summaries, EIP explainers, community-driven storytelling across blogs & videos.




{kind=link}